- Keyword research is not dead, but the unit of analysis changed: you now map entities, intent clusters, and answer formats instead of keyword strings ranked by search volume.
- AI search engines decompose every prompt into multiple synthetic sub-queries before any retrieval happens, so the keyword on the screen and the keyword the engine searches with are not the same.
- Volume-based research is functionally dead for mid-funnel AI visibility, but still holds for branded, transactional, long-tail commercial, and local queries.
- The framework is the Query Rewrite Gap: research the intent layer (what users want) and the synthesis layer (what gets cited), not just the invisible rewrite layer in between.
Table of Contents
Google’s “search query understanding” patent family, expanded through 2023 and 2024 to cover AI Overviews, describes a process that breaks the old keyword model. A single user query enters the system, and before the LLM writes a token, it is fanned out into between two and roughly ten synthetic queries. Each runs against the retrieval index separately. The final answer is composed from the union of those results. ChatGPT Search and Perplexity follow comparable architectures, with retrieval expansion and re-ranking steps that rarely surface the user’s original query verbatim.
This changes what “ranking for a keyword” means. You can hold position one on a query and be invisible in the AI answer for it, because the engine never ran that query against the index. It ran six others you may not have known existed.
The thing experienced marketers get wrong is treating AI search optimization as a new keyword problem requiring a new keyword tool. Keywords have stopped being the unit of supply. The supply unit is now the entity-and-intent pair, retrieved by synthetic queries you did not write. Search volume is a proxy for a layer the AI no longer searches.
This article covers how query fan-out works, why volume-based research breaks under it, what to research instead, where traditional keyword work still applies, and how to rebuild a workflow for both Google’s SERP and the citation surfaces of ChatGPT, Perplexity, Claude, and AI Overviews. If your traffic is sliding, the reasons your website is losing organic traffic and how AI is affecting SEO are companion reads.
What “AI rewrites every query” actually means
Three things happen between a user typing a query and seeing an AI-generated answer. None are visible. None are addressed by classic keyword tools.
Step one: query understanding. The system classifies the query by intent, ambiguity, freshness sensitivity, and entity references. “Best CRO tools for low traffic sites” is parsed into intent (commercial investigation), entities ([CRO tool], [low traffic website]), constraint (budget, simplicity), and freshness expectation (recent, current year).
Step two: query fan-out. The system generates synthetic queries that together cover the parse. Google’s patent language describes “related queries” and “implicit queries” expansions. In practice that produces a fan-out like:
CRO tools for small websites 2026best conversion rate optimization software low budgetCRO platform statistical significance low trafficpersonalization tools websites under 50000 visitorsA/B testing tools sample size minimum
Each sub-query is independently scored against the retrieval index. Pages compete inside each one. The user never typed any of these.
Step three: synthesis. Top-ranked passages from each sub-query are passed to the generator. The LLM produces an answer that may cite 3 to 8 sources, often from different sub-queries. A page that ranks #4 for the user’s literal query but #1 for two synthetic sub-queries gets cited. A page that ranks #1 for the literal query but matches no sub-query gets ignored.
The architecture is documented: Google’s patent applications describe it, ChatGPT Search’s citation panel confirms multi-query retrieval, and Perplexity surfaces its sub-queries directly in Pro mode.
Ranking and being cited are now two different problems with two different inputs. The classic SEO toolkit measures the first. AI search visibility depends on the second. If your keyword research workflow ends with a list of head-term targets and a volume column, you are optimizing for a retrieval step that has been demoted in the stack.

AI-engine traffic is also harder to attribute even when it converts: the query is invisible, and so is the sub-query that surfaced your page. The same dynamic now shapes GA4’s modeled and hidden data and the analytics platforms emerging beyond GA4.
Why the keyword-volume model collapses under query rewriting
Volume-based keyword research worked because search engines were string-matchers. Each query was an atom. You picked an atom with enough volume to be worth ranking for, produced a page targeted at it, and competed on signals tied to it.
Three structural problems break this under query fan-out.
- The first: the volume metric describes a query the retrieval step is no longer running. A keyword with 50,000 monthly searches still gets typed 50,000 times, but if the engine fans each into 8 synthetic queries, the retrieval-relevant demand is 400,000 atomized impressions across queries no tool reports. The volume is real; it is distributed across atoms you never targeted.
- The second: long-tail strategy inverts. Long-tail used to work because long-tail strings were specific enough to have low competition and precise intent match. Under fan-out, LLMs absorb long-tail queries into broader entity clusters during the parse step. “What’s a fair price for CRO consulting for a Shopify store doing $2M annually” gets decomposed into entity (Shopify store), intent (CRO pricing benchmark), and constraint ($2M revenue), then re-expanded into generic sub-queries about CRO pricing tiers. The long-tail page that targeted the original phrase competes against generic pricing pages and loses.
- The third: competing pages win by matching sub-queries you did not target. A competitor with a weaker page on the surface query may have stronger answer-format alignment for two or three synthetic sub-queries. It gets cited. You do not. Your rank tracker shows you at position 2 for the head term, your AI citation tracker shows you nowhere, and both reports are accurate.
This dynamic explains much of what looks like ranking volatility: the page has not moved, the retrieval has. It is also why SERP rank no longer generates sales on its own for many B2B sites, and why ChatGPT is taking traffic from Google in ways most rank trackers miss.
The Query Rewrite Gap
The framework this article uses is the Query Rewrite Gap: the space between what a user types and what an AI engine actually retrieves against. Three layers, and keyword research now happens at all three.
- Layer one: the intent layer. What the user is trying to accomplish. The query is a noisy signal of it. Marketers used to research this informally, then convert findings into a keyword list and forget about it until the next review. That conversion step now leaks too much information. Intent has to remain a first-class research artifact.
- Layer two: the rewrite layer. Where AI engines decompose intent into synthetic sub-queries. Invisible by default, but partially mappable: prompt AI engines directly, inspect Perplexity’s exposed sub-queries on Pro mode, analyze citation patterns across related head terms. Specialist tools (Profound, Otterly, Peec, SE Ranking’s AI Search module) are starting to surface this layer with patchy coverage.
- Layer three: the synthesis layer. What makes it into the generated answer: which sources get cited, in what order, with what extracted text. Synthesis is shaped by retrieval-passage quality, freshness, entity coverage, schema markup, and structural format, the same levers behind ranking on SearchGPT and Perplexity. A page that contains a clean answer to a sub-query in an extractable format gets quoted. A page that contains the same information buried in narrative does not.
Keyword research has moved up the stack from the rewrite layer to the intent layer, and forward to the synthesis layer. Layer two is partly mechanical and partly observable. Layers one and three are where the research effort now produces leverage.
Under classic SEO the keyword was the unit of work. Under AI search it is an intermediate artifact between an intent and a citation: you do not optimize for it directly, you use it to triangulate what you actually optimize for. This mirrors how intent data marketing moved post-click measurement away from source query toward observed behavior.
Entity research: the replacement for keyword strings
LLMs do not retrieve on strings the way classic search engines did. They retrieve on entity-weighted passages, where an entity is a named, structured thing with attributes (a company, product, person, framework, location, methodology). Strings signal that an entity is present. The entity itself is what the embedding model encodes and retrieves on.
This is why two pages with very different keyword targeting compete for the same citation: if both cover the same entity and attribute, they compete on entity coverage, not string density. It is also why exact-match anchor text matters less than it did.
The workflow shifts. Start from the topic you want to be cited for and list every entity in its neighborhood: products (yours and competitors), people (acknowledged experts), frameworks, platforms your audience uses, and adjacent categories. Verify each has a clear identity in Google’s Knowledge Graph and Wikidata, since both feed the LLM training and grounding corpus.
Inverse-prompting is the fastest way to find entity gaps. Run a query like “what are the most-cited CRO platforms in 2026” across ChatGPT, Perplexity, Claude, and Google AI Overviews, the practical core of getting ChatGPT to surface your products. The named entities in each answer are the ones the engines have associated with your topic. Anything missing that should be there is a gap. Anything that surprises you is a competing entity needing a dedicated comparison page.
Two warnings. Inverse-prompting is biased by training data, so it lags fast-moving categories and over-rewards entities with strong schema and Wikidata coverage. For B2B SaaS the gap is most acute on the product-led SEO surface; for e-commerce, mobile is the AI-search blind spot.
The cost is real. You spend more time on schema, entity-based internal linking, and named-entity disambiguation, and less on title-tag tuning. The payoff: entity coverage transfers between Google AIO, ChatGPT, Perplexity, and Claude in a way on-page keyword density does not.
Intent clustering: mapping the demand space, not the keyword space
Classic keyword tools (Ahrefs, Semrush, Google Keyword Planner) cluster keywords by lexical similarity, which is a weak proxy for intent. Two keywords with no shared tokens can represent the same intent. Two with substantial overlap can represent different intents. AI engines cluster on intent directly during the parse step, which means their fan-out groups are organized differently from the keyword groups in your tool.
The replacement is to cluster by underlying intent and decision stage, then back into keywords from there.
A working intent taxonomy has four dimensions:
- Stage: aligned to the buying journey (awareness, consideration, decision)
- Mode: problem-defining, options-comparing, solution-evaluating, vendor-validating
- Constraint: industry, size, budget, technical stack, regulatory
- Output expected: definition, list, comparison, recommendation, tutorial
For each cluster, write a short description, then enumerate the synthetic queries an AI engine is likely to generate from prompts in it. The engines themselves become research tools: prompt them with the intent description, ask what they would run internally, capture the answer. Imperfect, but it surfaces a fan-out skeleton your keyword tool will never show.
Then run the entity research from the previous section against each cluster, the same intent-data logic that drives revenue on the demand side. The intersection of intent cluster × entity coverage is the unit of work for your content team. A page is no longer “ranking for keyword X”; it is “covering intent cluster Y for entity Z in format W”. Brief that way.
The instinct to add more keywords is the wrong response to a sprawling keyword spreadsheet with diminishing returns. The right response is consolidation into 12 to 25 intent clusters, with entity coverage mapped per cluster, and an editorial calendar rebuilt around clusters rather than keywords. The page count goes down. The citation count goes up.
This is the same logic behind behavioral data in marketing: signals are clustered by intent, not by source query. The pre-click work has caught up to the post-click reality, which is also why customer journey mapping is the top CX-leader investment in 2026.
Where keyword research still works the same way
Not all queries get rewritten heavily. Four categories still respond to classic keyword research with minimal modification, and ignoring them is its own error.
- Branded queries. AI engines pass branded queries through with narrow fan-out because the entity is unambiguous. Volume on branded terms is a clean signal. Ranking position correlates closely with citation rate.
- Transactional and navigational queries with explicit intent markers. Phrases with transactional verbs (buy, download, sign up), explicit product modifiers (demo, free trial, login), or named features get rewritten minimally. Classic on-page keyword optimization works because the engine is essentially passing them through.
- Long-tail commercial queries with specific constraints. “Best CRO platform under $500/month with HubSpot integration” is constraint-laden enough that AI engines cannot expand meaningfully without losing the constraints. They retrieve directly against the original phrasing or a near-paraphrase. Long-tail commercial keyword research with explicit constraints still produces volume-correlated traffic, especially with comparison-format content.
- Local queries. Geographic constraints are rarely abstracted away during fan-out. Local intent generates local sub-queries, and Google AI Overviews defers heavily to Maps and local-pack results for these.
The pattern: AI engines preserve queries when the intent is unambiguous, the entities are concrete, or the constraints would be lost in abstraction. Whenever those conditions hold, classic keyword research is still the right tool and search volume still means what it used to.
Where research has changed most is informational (widest fan-out), commercial investigation (highest source diversity), and educational (highest synthesis). Most B2B SaaS content marketing lives in those buckets, which is why the shift feels universal even though it is not. For more on the surface-area question, see zero-click search optimization and how your company ranks on ChatGPT and Perplexity.
The new keyword research workflow
Six steps, in order.
Step one: start from intent, not volume. Begin every cycle with a list of intent clusters you want to own, scoped to your ICP and stage focus. The first artifact is a one-pager per cluster describing who has the intent, why, and what they expect to find. Volume enters as a tiebreaker, not a starting filter.
Step two: decompose target queries. For each cluster, generate 8 to 15 representative natural-language prompts (not keywords). Run each through ChatGPT, Perplexity, and Google AI Overviews. Capture the synthetic sub-queries (where exposed), cited sources, and answer structure. This is your fan-out skeleton.
Step three: map entities for each cluster. Build an entity inventory: products, people, frameworks, methodologies, regulations, platforms, comparison categories. Cross-reference with Google’s Knowledge Graph API and Wikidata. Identify gaps where competitors appear and you do not.
Step four: identify answer formats per engine. Google AIO favors structured lists, definitions, short paragraphs. Perplexity rewards data tables and explicit citations. ChatGPT pulls from comparison content and how-to guides. Map gaps by format-per-engine, not just by topic. The same logic applies on the technical SEO and on-page SEO basics layer underneath.
Step five: audit current content against the entity-and-format map. Walk the site against the cluster × entity × format matrix. Most teams find 60 to 80% of content is keyword-aligned but entity-thin or format-misaligned. The audit produces a rewrite-or-merge list, not a “produce more content” list.
Step six: prioritize by retrieval probability, not search volume. Estimate retrieval probability across engines based on entity coverage strength, format fit, freshness signals, and existing authority on adjacent clusters. Score and queue. This replaces the keyword-difficulty-vs-volume matrix.
The output is a content backlog organized by intent cluster, with explicit entity, format, and engine targets per piece. Head terms still appear in titles and headers, but they are downstream artifacts of the research, not its anchor.
Teams already on a topic-cluster model migrate easily. Teams still on page-per-keyword should expect a quarter of consolidation before new production resumes. Running this alongside paid, the question of whether paid lead generation brings volume but not qualified buyers is the same problem on a different channel.
Tool stack: what changes, what doesn’t
Still useful, narrower scope: Ahrefs, Semrush, Moz, Google Keyword Planner. Volume data remains accurate for the surface query, which still matters for branded, transactional, navigational, and long-tail commercial work. Backlink and authority metrics matter more than before, since entity authority correlates with citation probability. The use case that breaks is mid-funnel informational keyword strategy. For where they still apply cleanly, see the best CRO tools worth paying for and CRO testing approaches that still consume volume-based keyword inputs.
New layer, becoming necessary: AI search visibility trackers like Profound, Goodie AI, Otterly, Peec, and SE Ranking’s AI Search module. These track citation appearances across ChatGPT, Perplexity, Google AIO, and Claude for tracked prompts. Treat them like rank trackers in 2010: imperfect, worth running, do not over-trust the absolute numbers.
Manual prompt-testing is essential. No tool surfaces the full sub-query fan-out across engines consistently, so a weekly cadence of running priority prompts and capturing the citation panel remains the highest-fidelity signal. Document it, assign it, review it.
Schema and structured-data tools matter more. Schema.org validator, Google’s Rich Results Test, and dedicated schema generators are load-bearing for entity legibility. If your team treated schema as a checklist item, it needs to become a workflow. This is also why SEO is changing with SearchGPT in ways the average content audit misses.
Analytics platforms split. GA4 continues to misreport AI search traffic because referrer information is stripped by many AI engines, which is part of why conversational analytics is replacing manual report-building. Treat referrer-based attribution as a directional signal at best.
The workflow tool you do not have yet is an entity-coverage tracker. The best practical substitutes are a maintained spreadsheet, Knowledge Graph API queries, and a regular inverse-prompting cadence. Expect this category to develop through 2026.
How Pathmonk converts AI search traffic without needing the keyword
The blind spot in AI search is that the query is invisible. The visitor arrives, sometimes without a referrer, sometimes with only the AI engine domain attached, and the question that brought them is locked inside the engine’s session. You cannot personalize off it because you cannot see it. The classic conversion playbook depends on knowing what the visitor searched for. Most of it stops working.
Pathmonk addresses this from the opposite direction. It reads intent from behavior on the page in real time, across 200+ behavioral signals, rather than from the inbound query. The real-time intent engine runs on first-party, cookieless behavioral data and assigns each visitor a stage in the buying journey (awareness, consideration, decision), updated as they navigate. The classifier does not need to know what the AI engine retrieved on your behalf. It infers from scroll depth, dwell, page sequence, pricing-page returns, and roughly 200 other signals.
Once intent is classified, Pathmonk renders a microexperience: a contextually appropriate supporting message, social proof block, or content surface that raises the probability of the visitor completing the existing conversion goal, the same job exit-intent popups did badly and now do worse against AI-search visitors. The conversion goal itself stays the same for every visitor; what changes is the supporting context around it, matched to where the visitor is in their decision. Each microexperience inherits brand styling automatically from Company DNA, so it reads as native rather than as a bolted-on widget. The Performance Hub runs A/B tests on live traffic starting at a 50/50 split, runs each test to 95% statistical confidence against a permanent 5% control group, and keeps the winners while cutting the losers. Lift is measured per card, not assumed.
There is a second, less obvious lever. The acquisition side of AI search is not only about being cited; it is about being actionable inside the engine. Pathmonk’s Website MCP exposes your brand and your conversion actions to AI tools through the Model Context Protocol, so a buyer researching inside ChatGPT, Claude, or Perplexity can book a demo, sign up, or buy without leaving the conversation. This is the part of the stack built for the world this article describes: buyers now assemble their shortlist inside an AI engine before they ever reach your homepage, and Website MCP makes the brand transactable at that point rather than waiting for a click that may never come. It is the backbone of LEO (LLM / AI search optimization), the AI-engine equivalent of the SEO layer.
The attribution gap closes from the same direction. Pathmonk’s Bing AI referrals connector surfaces LLM-referred traffic that standard analytics drops, so you can see which AI-generated answers send visitors to which pages. The Search Console connector lets you serve different microexperiences to branded versus non-branded query arrivals automatically, which restores some of the intent signal that fan-out strips out before the visitor lands.
Let AI assistants book, buy, and sign up on your behalf
- Your website becomes transactable inside ChatGPT, Claude, and Perplexity
- Buyers convert without ever leaving the AI conversation

LAW GROUP
- Practice
- About
Employment Law Representation You Can Rely On
Protecting your rights. Securing favorable outcomes.
Case study: How Ausbildung-Weiterbildung multiplied lead generation when their organic traffic shape shifted
Ausbildung-Weiterbildung is one of Germany’s largest education marketplaces, with most of its visitor acquisition coming from organic search. The economics depend on converting search traffic into qualified leads for training providers, historically a volume-driven model.
As AI Overviews and ChatGPT Search began absorbing informational education queries, the visitor profile shifted: visitors arrived with more pre-purchase research done and less patience for navigation.
- The acquisition layer was largely working
- The conversion experience was not adapting to changing visitor intent
- The team had limited engineering bandwidth to rebuild journey flows manually
- Visitor data was rich, but not actionable in real time
- Adding more keywords no longer produced matching uplift
The team had no shortage of traffic. They had a shortage of contextual response to that traffic.
They deployed Pathmonk on the high-intent pages and let the intent engine run against existing visitor behavior. Microexperiences were matched to awareness, consideration, and decision-stage intent against the existing conversion goal of training-provider lead capture.
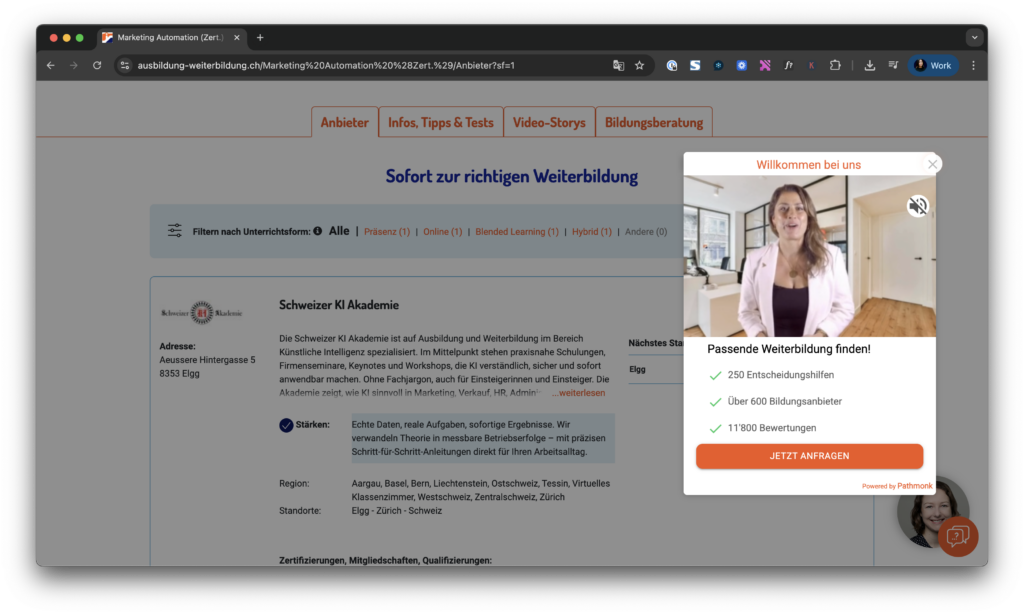
- +87% leads in the first week of activation
- Improvements compounded across multiple training categories without per-category configuration
- The team did not need to instrument anything about the inbound query
When the acquisition surface gets harder to predict, the durable lever is the conversion surface, and the durable mechanism is intent classification on behavior rather than on inbound query.
FAQs on keyword research in times of AI
Is keyword research dead?
No. Volume-based keyword research as the primary strategic anchor is functionally dead for mid-funnel informational content in AI search. It remains directly useful for branded, transactional, navigational, long-tail commercial, and local queries. The discipline has moved up the stack, not disappeared.
How is keyword research different for ChatGPT vs Google AI Overviews vs Perplexity?
Each engine fans out differently. ChatGPT favors comparison-format and how-to content, with citations skewed toward authoritative domains. Google AIO prefers structured lists, definitions, and short paragraphs from sources with strong schema. Perplexity rewards data-rich tables and explicit citation density. A page that does well in one is not guaranteed to do well in another, which is why per-engine answer-format mapping is now part of the workflow.
Should I still use Ahrefs and Semrush?
Yes, with narrower scope: branded, transactional, long-tail commercial, and local research where volume still predicts traffic, plus backlink and authority analysis, which matters more than before. Stop using volume as the primary prioritization signal for mid-funnel informational content.
What is entity research in practice?
Listing the named things in a topic (products, people, frameworks, platforms, methodologies), verifying each has a clear identity in Google’s Knowledge Graph and Wikidata, and mapping which entities competitors are associated with that you are not. The output is a list of entities and association gaps, not keyword strings.
How do I see the synthetic sub-queries an AI engine generates?
Perplexity surfaces them directly in Pro mode. ChatGPT and Google AIO do not, but inverse-prompting (asking the engine what it would search for) returns approximate fan-outs. Specialist tools (Profound, Otterly, Peec, SE Ranking AI Search) are starting to surface sub-query data at patchy coverage. Manual capture remains essential.
Does this mean topic clusters are now obsolete?
The opposite. Topic clusters become more important because they map cleanly to intent clusters, which is what AI engines retrieve against during fan-out. What changes inside the cluster is the unit of work: pages now target intent-and-entity pairs rather than head terms with supporting long-tail.
How do I attribute AI search traffic?
Imperfectly. GA4 referrer reporting is inconsistent because many AI engines strip or proxy referrers. The most reliable signal combines branded-search uplift, direct traffic correlated with category AI-search volume, and conversion-side behavioral data on visitors arriving without UTM markers. On-site behavioral classification beats referrer-based attribution here.
Does AI search visibility require new schema markup?
It rewards it. Article, FAQ, HowTo, Product, and Organization schema all increase entity legibility. Schema is necessary but not sufficient: a page with perfect schema but weak entity coverage is still passed over. Schema makes you legible; entity coverage determines whether you get cited.
How often should I re-run AI search citation tracking?
Weekly for priority prompts, monthly for full cluster coverage. The engines retrain on different schedules and citation patterns drift faster than classic SERP positions. A weekly cadence catches the drift before it compounds.
What is the single biggest mistake teams make migrating to this workflow?
Adding AI-search work on top of existing keyword work instead of consolidating. Most backlogs are 60 to 80% keyword-aligned but entity-thin, so a consolidation pass beats new production. Teams that add without consolidating end up with double the spreadsheet and the same citation rate.
Key takeaways
- Volume-based keyword research is functionally dead for mid-funnel informational AI search visibility, but remains accurate for branded, transactional, long-tail commercial, and local queries
- AI engines decompose every user prompt into 2 to 10 synthetic sub-queries before retrieval, and citations go to pages matching the sub-queries, not the original query
- The replacement framework is the Query Rewrite Gap: research at the intent layer (what users want), the rewrite layer (what AI engines actually retrieve), and the synthesis layer (what gets cited)
- Entities replace keyword strings as the unit of retrieval; intent clusters replace lexical keyword groups
- Workflow shifts from “keyword × difficulty × volume” to “intent cluster × entity coverage × answer format × retrieval probability”
- Existing keyword tools narrow in scope; AI citation trackers, schema tooling, and manual prompt-testing become load-bearing
- Acquisition-side AI search optimization is durable but slow; conversion-side optimization compounds against every traffic source and is more controllable
- When the inbound query is invisible (typical for AI search traffic), behavioral intent classification on the page replaces query-based personalization