
The Autonomy Ladder
Autonomy is graded, not a switch
Where a marketing agent sits on this ladder should be a deliberate choice. Errors compound at every step, so narrow scope beats broad ambition.
Lower autonomyHigher autonomy and higher risk
Rung 1
Suggest
Surfaces a recommendation. A human acts on it.
Rung 2
Draft
Produces the asset. A human ships it.
Rung 3
Execute with approval
Takes the action, then pauses at a defined gate.
Rung 4
Execute autonomously
Acts within hard constraints, no per action review.
2026 reality
Most production marketing agents sit on the middle two rungs, which is the correct place given current reliability.
44%
Success of a 5 step workflow at 85% per step accuracy
20%
Success of a 10 step workflow at 85% per step accuracy
24%
Real world tasks the best models finished first try (APEX Agents 2026)
An autonomous agent is only as trustworthy as its weakest step multiplied across every step it takes.
The Agent Substrate
The model is rented. The substrate is the build.
Four layers sit beneath the model. Each one is a place an autonomous marketing agent fails when it is missing.
M
The model
Every team calls the same API. The per step quality gap is small.
Commodity
The Agent Substrate
Your moat
1
Grounding data
First party behavioral signal: what real visitors actually do on your site, impossible to buy.
Missing it: cold start, guessing
2
Knowledge layer
A structured profile of brand, products, positioning and proof, so output is specific, not generic.
Missing it: off brand output
3
Action surface
Tools and MCP, scoped to exactly what the agent may touch and what it must gate.
Missing it: silent tool failures
4
Governance
Approval gates, control group measurement and an audit log that decide whether autonomy is earned.
Missing it: cancelled project
The model is rented and shared. The substrate is yours alone, and it is where marketing agents succeed or fail.
Grounded vs Ungrounded
Same model, opposite outcomes
The model in the middle is identical. What the agent is fed decides whether its output is specific and reliable, or plausible and generic.
Ungrounded agent
Fed by a bought third party list and a generic model
Plausible, generic
x
Data source. Rented lists and category assumptions.
x
Brand fit. Output could belong to any competitor.
x
Real behavior. Blind to what visitors actually do.
x
Compounding. No loop from action back to signal.
Grounded agent
Fed by first party behavioral signal and a brand profile
Specific, reliable
+
Data source. Your own site behavior, impossible to buy.
+
Brand fit. One profile keeps every agent on brand.
+
Real behavior. Reads intent and stage in real time.
+
Compounding. Each result sharpens the next decision.
The pilots that fail share one trait: they are not grounded in first party context, which is why narrowing the model choice never fixes them.
The Approval Gate
One checkpoint at the highest risk step
The orchestration pattern that captures most of the autonomy benefit while removing most of the catastrophic failure risk.
Step 1
Detect
High intent lead from behavioral signal.
›
Step 2
Enrich
Pull context from the knowledge layer.
›
Step 3
Draft
Generate personalized outreach.
›
Gate
Approve?
Risk check before anything leaves.
High risk path
Human signs off. External email, budget spend and record changes wait here.
Low risk path
Reversible, scoped actions execute without waiting for a person.
⚠
Autonomy without a gate fails the moment an edge case the agent never saw arrives, which deployment studies put inside the first 60 seconds of real traffic.
Treat any irreversible action as gated by default. The gate is the single governance control that does the most work.
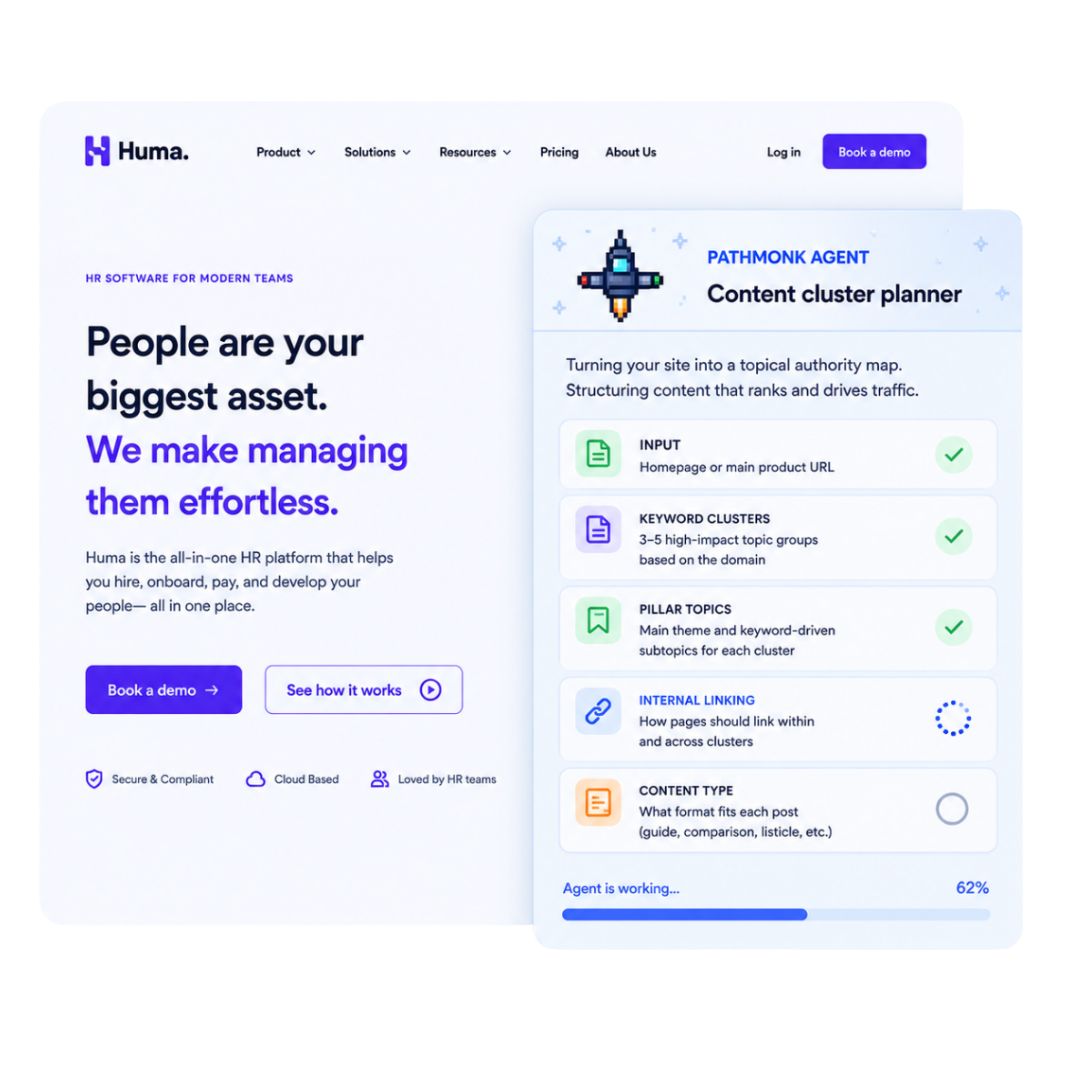
Agents you can run
Build any marketing agent you need
Each agent owns one repeatable task. Start with one, add more as work comes up, and they all run on the same grounded substrate.
Content & organic
Content production
drafts and repurposes from your library
Content refresh
updates decaying pages
Social repurposing
posts, threads, carousels
AI search & reputation
SEO & AI visibility
rank and get cited
LLM citation monitor
how AI describes your brand
Review responses
drafts replies, surfaces themes
Demand & sales
Lead enrichment & routing
ranks and routes inbound
Outreach & backlinks
pitches and follow-ups
Sales enablement
battlecards, one-pagers
Intelligence & ops
Competitor tracker
pricing and messaging diffs
Analytics digest
weekly plain-language readout
Localization
adapts per market
One substrate
Every agent runs on your first-party behavioral data and a profile of your brand, not a rented model and a bought list.
Build the agent you need, ground it in your own data, and add to the fleet as new work comes up.