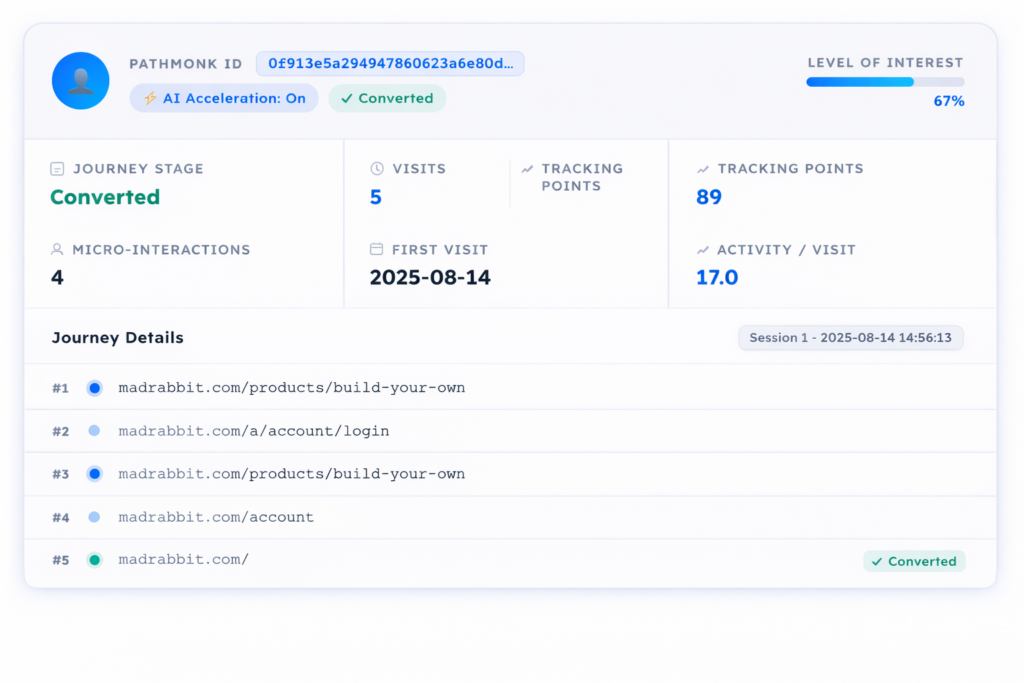

Qualification framework
The signal matrix: ICP fit × behavioral intent
Four qualification states, each requiring a different sales motion. Position a lead by crossing its firmographic fit against its observed behavioral signals.
Low behavioral intent
High behavioral intent →
High ICP fit ↑
Low ICP fit
Nurture
ICP fit, not yet in-market
Profile matches but behavioral signals are absent or stale. Do not send to sales. High risk of wasting SDR time and souring the relationship before readiness.
Automated nurture
Re-score on trigger
No SDR yet
⚡
Fast-track T1
High ICP + high intent
Both signals aligned. This is the only quadrant that warrants same-day SDR outreach. Every hour of delay reduces conversion probability.
Immediate SDR
Same-day routing
AE priority
Deprioritize
Low fit, low engagement
Neither firmographic nor behavioral signals justify resource allocation. Marketing-only or exclude entirely from active sequences.
Marketing only
Low-cost channel
No SDR allocation
Investigate
High intent, ICP mismatch
Strong behavioral signals but firmographics don't fit. Before discarding: verify the ICP data, check for a champion scenario, or flag for a low-cost touch to confirm intent.
Verify ICP data
Check champion
Light-touch only
How to use this matrix: Score every lead on two independent axes. ICP fit uses firmographic + technographic data (static). Behavioral intent uses time-weighted engagement signals (decays). Quadrant placement drives routing, not a single threshold score. Re-evaluate position every 14 days. A lead can move from Nurture to Fast-track in a single session.
⚠
Most common error: treating all leads with a high ICP score as T1 regardless of behavioral state. A contact from a perfect-fit company with no engagement in 60 days belongs in Nurture, not the Fast-track queue.
Score decay model
How behavioral signals lose weight over time
Every engagement signal carries a half-life. The same action scored at day 3 and day 60 should not contribute equally to a lead's qualification tier.
Page visit
Website engagement
Email open
Campaign engagement
Content download
Gated asset conversion
ICP / firmographic
Profile attribute
Full weight — counts 100%
Half weight — counts 50%
Zero — signal expired
Implementation note: Apply decay at the MAP or CRM layer by storing the original signal timestamp and computing weighted score at query time. Do not bake decay into a static point value at the moment of ingestion — a re-engagement event should reset the clock, not compound on a stale base score.